Inilabas ng Nvidia ang Malaking Accelerator Memory: Solid-State Storage para sa mga GPU
Nangangako ang DirectStorage application programming interface (API) ng Microsoft na pagbutihin ang kahusayan ng paglilipat ng data ng GPU-to-SSD para sa mga laro sa isang kapaligiran sa Windows, ngunit nakahanap ang Nvidia at ang mga kasosyo nito ng paraan para maayos na gumana ang mga GPU sa mga SSD nang walang proprietary API. Ang pamamaraan, na tinatawag na Big Accelerator Memory (BaM), ay nangangako na magiging kapaki-pakinabang para sa iba’t ibang mga gawain sa pag-compute, ngunit ito ay magiging partikular na kapaki-pakinabang para sa mga umuusbong na workload na gumagamit ng malalaking dataset. Sa pangkalahatan, habang ang mga GPU ay lumalapit sa mga CPU sa mga tuntunin ng pagiging program, kailangan din nila ng direktang access sa malalaking storage device.
Ang mga modernong graphics processing unit ay hindi lamang para sa mga graphics; ginagamit din ang mga ito para sa iba’t ibang heavy-duty na workload tulad ng analytics, artificial intelligence, machine learning, at high-performance computing (HPC). Upang maproseso nang mahusay ang malalaking dataset, ang mga GPU ay maaaring nangangailangan ng malalaking halaga ng mamahaling espesyal na layunin ng memorya (hal., HBM2, GDDR6, atbp.) nang lokal, o mahusay na pag-access sa solid-state na storage. Ang mga modernong compute GPU ay nagdadala na ng 80GB–128GB ng HBM2E memory, at ang mga susunod na henerasyong compute GPU ay magpapalawak ng lokal na kapasidad ng memorya. Ngunit mabilis ding tumataas ang mga laki ng dataset, kaya mahalaga ang pag-optimize ng interoperability sa pagitan ng mga GPU at storage.
Mayroong ilang pangunahing dahilan kung bakit kailangang pagbutihin ang interoperability sa pagitan ng mga GPU at SSD. Una, ang mga tawag sa NVMe at paglilipat ng data ay naglalagay ng maraming load sa CPU, na hindi mahusay mula sa pangkalahatang pagganap at kahusayan na pananaw. Pangalawa, ang overhead ng overhead ng pag-synchronize ng CPU-GPU at/o I/O traffic amplification ay makabuluhang nililimitahan ang epektibong storage bandwidth na kinakailangan ng mga application na may malalaking dataset.
“Ang layunin ng Big Accelerator Memory ay palawigin ang kapasidad ng memorya ng GPU at pahusayin ang epektibong bandwidth ng access sa storage habang nagbibigay ng mga abstraction ng mataas na antas para sa mga thread ng GPU upang madaling makagawa ng on-demand, pinong-grain na access sa napakalaking istruktura ng data sa pinalawak na hierarchy ng memorya. ,” isang paglalarawan ng konsepto ng Nvidia, IBM, at Cornell University na binanggit ng The Register.
(Kredito ng larawan: Ang Register)
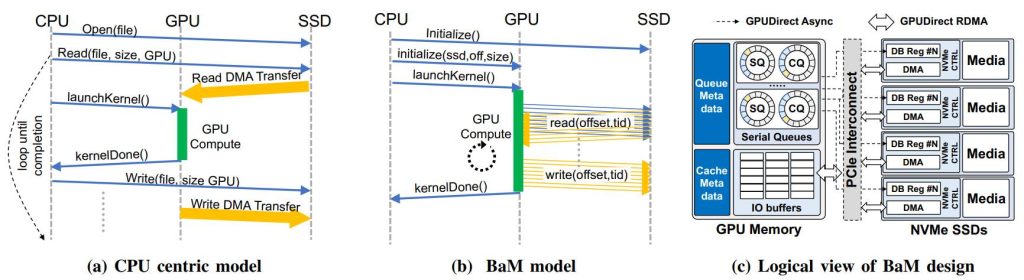
Mahalagang binibigyang-daan ng BaM ang Nvidia GPU na kumuha ng data nang direkta mula sa memorya ng system at storage nang hindi ginagamit ang CPU, na ginagawang mas self-sufficient ang mga GPU kaysa sa ngayon. Ang mga Compute GPU ay patuloy na gumagamit ng lokal na memorya bilang software-managed cache, ngunit maglilipat ng data gamit ang isang PCIe interface, RDMA, at isang custom na Linux kernel driver na nagbibigay-daan sa mga SSD na direktang magbasa at magsulat ng GPU memory kapag kinakailangan. Ang mga utos para sa mga SSD ay naka-queue ng mga GPU thread kung ang kinakailangang data ay hindi available sa lokal. Samantala, ang BaM ay hindi gumagamit ng virtual memory address translation at samakatuwid ay hindi nakakaranas ng mga serialization event tulad ng TLB miss. Plano ng Nvidia at ng mga kasosyo nito na i-open-source ang driver para payagan ang iba na gamitin ang kanilang konsepto ng BaM.
“Binabawasan ng BaM ang paglaki ng trapiko ng I/O sa pamamagitan ng pagpapagana sa mga thread ng GPU na magbasa o magsulat ng maliliit na halaga ng data on-demand, ayon sa tinutukoy ng pag-compute,” sabi ng dokumento ng Nvidia. “Ipinapakita namin na ang software ng imprastraktura ng BaM na tumatakbo sa mga GPU ay maaaring tukuyin at ipaalam ang mga fine-grain na pag-access sa isang sapat na mataas na rate upang ganap na magamit ang pinagbabatayan na mga storage device, kahit na may mga consumer-grade SSD, maaaring suportahan ng isang BaM system ang pagganap ng application na mapagkumpitensya. laban sa isang mas mahal na DRAM-only na solusyon, at ang pagbawas sa I/O amplification ay maaaring magbunga ng makabuluhang benepisyo sa pagganap.”
Sa isang malaking antas, ang BaM ng Nvidia ay isang paraan para makakuha ang mga GPU ng malaking pool ng storage at gamitin ito nang hiwalay mula sa CPU, na ginagawang mas independent ang mga compute accelerators kaysa sa ngayon.
Matatandaan ng matatalinong mambabasa na sinubukan ng AMD na pakasalan ang mga GPU na may solid-state na storage gamit ang Radeon Pro SSG graphics card nito ilang taon na ang nakararaan. Habang ang pagdadala ng karagdagang storage sa isang graphics card ay nagbibigay-daan sa hardware na ma-optimize ang access sa malalaking dataset, ang Radeon Pro SSG board ay idinisenyo lamang bilang isang graphics solution at hindi idinisenyo para sa mga kumplikadong compute workload. Ang Nvidia, IBM, at iba pa ay gumagawa ng mga bagay nang higit pa sa BaM.